Introducción
El ciclo de vida de los datos en un proyecto de Data Science, hace referencia al proceso completo desde cómo se generan hasta cómo finalmente se eliminan. Estas etapas son fundamentales para garantizar que los datos se gestionen de manera eficiente y efectiva. A continuación, veremos una a una a que se dedica cada etapa del ciclo de vida de los datos de un proyecto de Data Science.
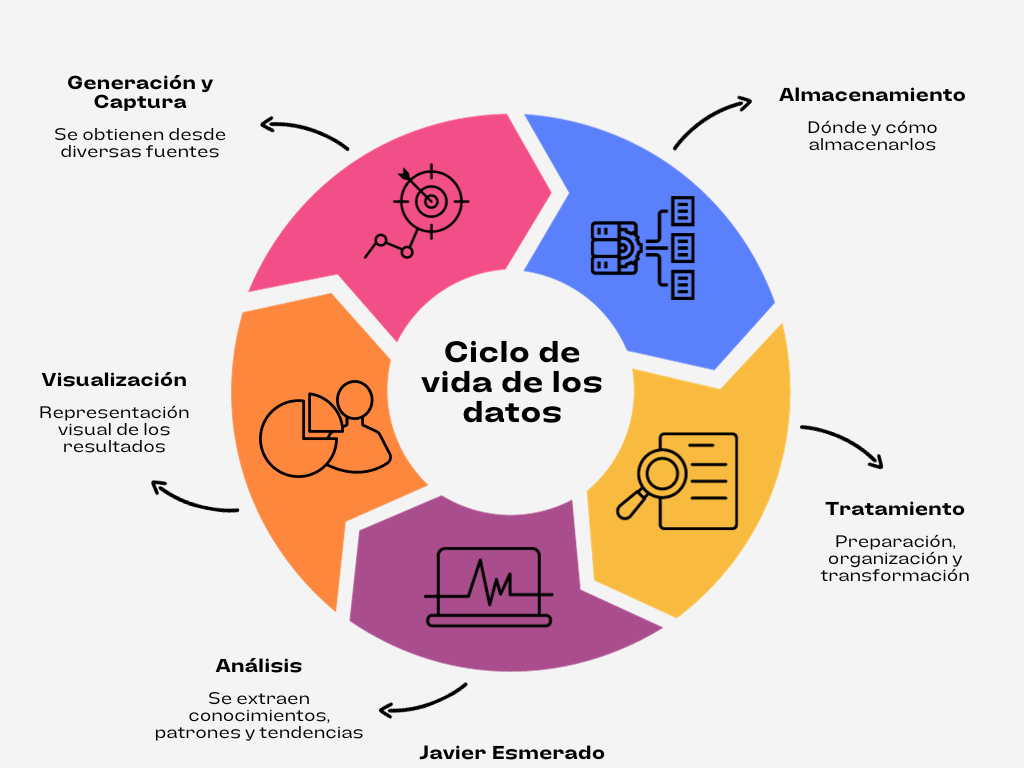
Primera etapa: Generación y Captura de Datos.
El primer paso de este ciclo, es la generación y captura. Estos datos pueden ser generados desde diversas fuentes, sensores, aplicaciones, transacciones, encuestas, registros, medios sociales, bases de datos, entre otros. En esta etapa, es esencial identificar y definir qué datos se deben recopilar y con qué propósito. La calidad y precisión de los mismos son un aspecto crítico.
Algunos de los métodos de captura que se utilizan para la obtención de datos son:
- Captura Manual. Los usuarios se encargan de ingresar datos directamente a una aplicación o sistema. Muy común en formularios u hojas de cálculo.
- Sensores. Sensores de temperatura, sensores de movimiento, cámaras, monitores de frecuencia cardíaca o medidores de energía.
- Web Scraping. Utilizando programas informáticos para extraer datos de páginas web con el fin de obtener datos de interés público.
- Integración de Sistemas. Como por ejemplo APIs (Application Programming Interface) o ETL (Extract, Transform, Load).
- Captura Automatizada de Registos. Registros de red o tráfico de datos.
Una vez que todos estos datos han sido recopilados, es necesario almacenarlos de alguna manera, lo que nos conduce a la segunda fase del proceso.
Segunda Etapa: Almacenamiento de Datos.
Una vez generados, los datos deben almacenarse en sistemas o bases de datos apropiados. Esto implica decir dónde y cómo almacenarlos, establecer políticas de retención y asegurar que los datos se encuentren disponibles y seguros. La escalabilidad y la eficiencia del almacenamiento son claves en esta etapa.
Estos datos pueden ser clasificados en:
- Datos no estructurados (Imágenes, textos, PDF).
- Datos estructurados (BBDD Relacionales, CSV).
- Datos semi estructurados (XML, JSON).
La estructura con la que los datos pueden ir variando en función de la etapa del proceso en la que se encuentren.
Podríamos profundizar en cada tipo de estructura, sin embargo, prefiero reservar un artículo completo para un análisis detallado de cada uno de ellos.

Tercera Etapa: Tratamiento de Datos.
En esta tercera etapa es esencial ya que se refiere a la preparación, organización y transformación de los datos recopilados y almacenados para que sean utilizables en el análisis, informes y aplicaciones. Al llegar a esta etapa, los datos suelen estar crudos, desordenados y pueden contener errores, duplicados o valores ausentes.
Podemos diferencias diferentes fases:
- Limpieza de Datos. Se identifican y corrigen los errores, valores atípicos y datos faltantes. Esto implica eliminar duplicados, corregir errores, rellenar valores ausentes o eliminar registros no válidos. Esta fase es esencial para garantizar la precisión y la confiabilidad de los análisis subsiguientes.
- Integración de Datos. Los datos suelen ser recopilados de múltiples fuentes y formatos. En esta etapa, se combinan y se integran en una única fuente de datos coherente y uniforme. Esto puede requerir la transformación de los mismos para que todos sigan un formato estándar.
- Transformación de Datos. Esta fase implica aplicar cambios a los datos para adecuarlos al análisis. Esto puede incluir la normalización de datos, la conversión de unidades de medida, la codificación de variables categóricas y la agregación de datos en diferentes niveles de granularidad.
- Control de Calidad de Datos. La calidad de los datos es fundamental. Se establecen criterios y métricas para evaluar la calidad de los mismos, como la integridad, consistencia y la exactitud.
- Segmentación de Datos. A menudo, se dividen los datos en segmentos o se crean subconjuntos para un análisis más detallado.
- Gestión de Cambios. Los datos son dinámicos y pueden cambiar con el tiempo. Es importante establecer procesos para gestionar cambios en los datos y garantizar que la información se mantenga actualizada.

Cuarta Etapa: Análisis de Datos.
La cuarta etapa, es el núcleo de todo el proceso, es dónde se extraen conocimientos, patrones y tendencias de los datos recopilados y preparados.
A continuación desarrollaré con más detalle esta cuarta etapa:
- Selección de Técnicas de Análisis. Se eligen las técnicas de análisis adecuadas según los objetivos del proyecto. Las técnicas pueden ser estadísticas, de aprendizaje automático, o cualquier otro enfoque que se ajuste a los datos y las preguntas a responder.
- Exploración de Datos. Antes de aplicar técnicas avanzadas de análisis, es común realizar una exploración inicial. Esto implica la generación de gráficos, tablas y resúmenes estadísticos para poder comprender mejor la distribución de los datos y evaluar la correlación entre variables. Herramientas cómo Python son ampliamente utilizadas en esta fase.
- Análisis Estadístico. Se utiliza para comprender la variabilidad de los datos y realizar inferencias sobre poblaciones o fenómenos. Se puede realizar pruebas de hipótesis, análisis de varianza o regresiones para obtener información significativa.
- Aprendizaje Automático (Machine Learning). El análisis automático desempeña un papel importante. Se utilizan algoritmos de aprendizaje automático para crear modelos predictivos y descriptivos. Esto incluye clasificación, regresión, agrupación y tareas de procesamiento del lenguaje natural (NLP). Las herramientas populares incluyen scikit-learn, TensorFlow, y PyTorch.

Quinta Etapa: Visualización de Datos.
Esta última etapa, es un componente esencial del análisis de datos. En esta, los resultados y patrones extraídos de los datos se presentan de manera visual mediante gráficos, gráficos interactivos y otras representaciones visuales. La visualización es crucial para comunicar de manera efectiva la información a los interesados y tomar decisiones informadas.
A continuación profundizaremos en esta etapa:
- Selección de Tipos de Gráficos. Se debe elegir el tipo de gráfico más adecuado para representar los datos y resultados. Las opciones van desde gráficos de barras, circulares, de dispersión hasta mapas de calor o líneas de tiempo. Esta elección depende de la naturaleza de los datos.
- Diseño de Gráficos Efectivos. Los gráficos deben ser claros, legibles y atractivos. Se deben elegir colores, etiquetas y títulos de manera cuidadosa para una compresión fácil y rápida.
- Tableros de Control (Dashboards). Son un conjunto de visualizaciones que se utilizan para mostrar un panorama completo de los datos y las métricas. Son útiles para monitoreo a tiempo real o toma de decisiones empresariales.
- Herramientas de visualización.
- Tableau: Una popular herramienta de visualización que permite crear gráficos interactivos y tableros de control.
- Power BI: Una herramienta de visualización de datos de Microsoft que permite crear informes y visualizaciones interactivas.
- Matplotlib y Seaborn: Bibliotecas de Python ampliamente utilizadas para crear visualizaciones estáticas y dinámicas.
- D3.js: Una biblioteca de JavaScript para crear visualizaciones de datos personalizadas y altamente interactivas.
- Comunicación de Resultados. Todo lo anterior se utiliza para comunicar hallazgos a audiencias, los resultados se presentan en informes, presentaciones, documentos y presentaciones visuales.

Conclusiones
Este post ha sido un poco más largo, pero espero que a grandes rasgos se haya podido comprender este ciclo.
A partir de este aquí y una vez que ya podemos tener un contexto de que es la ciencia de datos y a que puede llegar a dedicarse un Científico de datos, me gustaría empezar a compartir posts más prácticos y mucho más interesantes.
¡Espero que lo hayas disfrutado! 🚀
¡Hasta la próxima! 👋🏻